Figure 1: An example of an annotation
Niqui O’Neill is the Digital Technologies Development Librarian at North Carolina State University who took the time to explain her recent project using IIIF (International Image Interoperability Framework):
Tell us more about your work:
I have been working on three projects that provide users the ability to create and use annotations on IIIF resources. The International Image Interoperability Framework (IIIF) is a set of standards that provides users with easier access to high quality images. It does this by providing four standardized APIs that are structured in JSON. The Image API provides image bitstreams and corresponding metadata. The Presentation API can define which images belong to a multi-image object, like a book or manuscript, provide metadata, etc. It does this by creating a file called a manifest. The Authentication API provides authentication procedures and the Content Search API allows for searching the annotations listed in a manifest. Not all of these APIs have to be used in order to be IIIF compliant. Many institutions only use the Image API. I would suggest reading this article by Tom Crane for a more in depth introduction to IIIF.
My projects look to provide open and accessible tools for annotations of IIIF images. In this context, annotations are JSON objects in OpenAnnotation or W3 annotation standard that reference portion of an image with corresponding text, tagging, etc.
Annotations currently serve a useful purpose in the Content Search API providing full text search, but there are very few applications that capitalize on the full capabilities of annotations. Those that do are not easily usable, open and most of them require the annotations to be defined in the manifest (via the Presentation API). When we started exploring annotations we were concerned specifically with using existing annotations. My department head, Jason Ronallo, is really involved in the IIIF community and saw an opportunity to start making use of annotations outside full text search. Our main goal is to not only provide tools for scholarly research, teaching and visualization but developing these tools to be flexible enough that new and unique uses can be utilized from multiple communities.
In order to make use of the existing annotations, I created a JavaScript library that takes an annotation url and renders the annotation. According to IIIF standards the url(s) of the annotations are listed in the manifest of a resource. However, I decided to use the annotation urls as a data source to make the tool usable on a wider range of images and to reduce user labor. If the manifest had been used as the data source, external users would have had to create and host their own separate manifest.
The JavaScript library has two presentation formats: the image viewer and the storyboard viewer. The image viewer allows users to display the annotated portion of the image, the annotations, the full image, and a link to the full object if available. The image viewer also has settings that allow for image only renderings, specialized heights, and hiding specific elements. An example can be seen below (Figure 3). In order to render either of the formats the JavaScript library is loaded into the HTML page (Figure 2). Then the tag for the image viewer is loaded with the url of the annotation (see purple box in Figure 3). The url property is dependent on the type of annotation which is listed in the annotation in the ‘type’ field. Annotationurl for single annotations and annotationlist for AnnotationList or AnnotationPage.
![]()
Figure 2: Loading Javascript Library
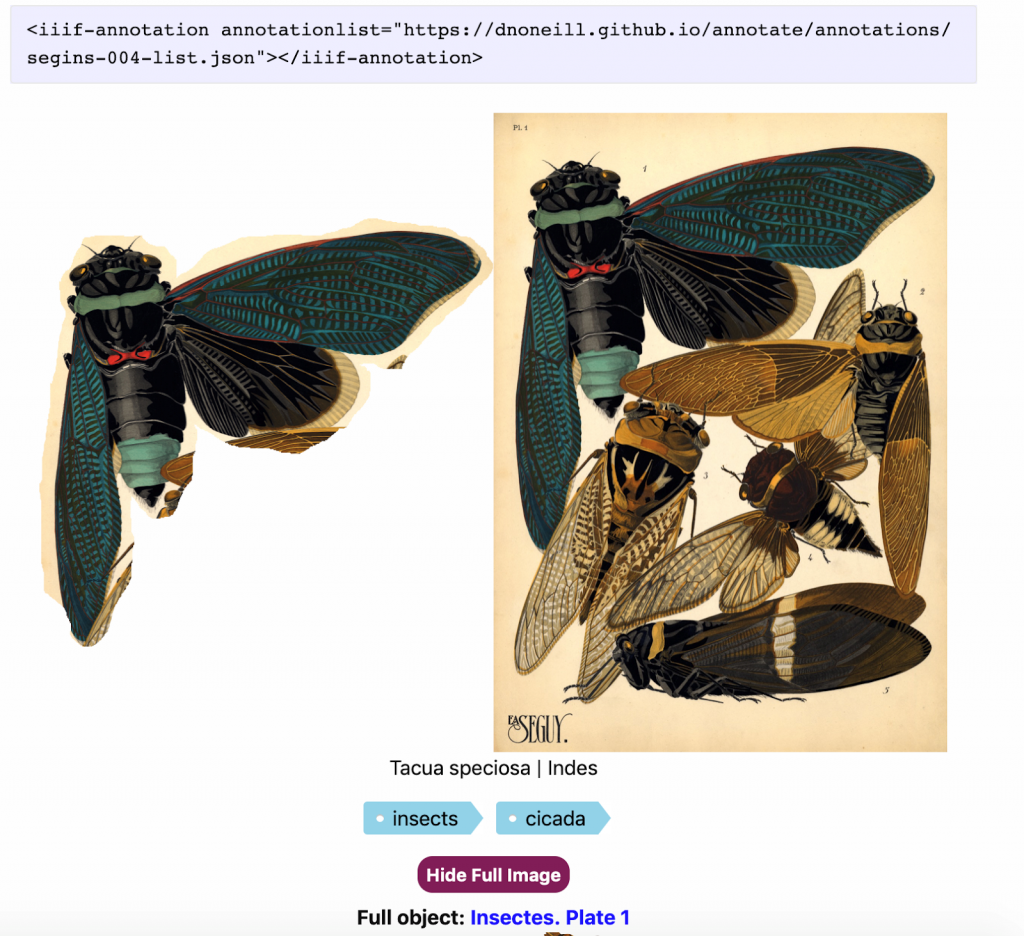
Figure 3: Rendered AnnotationList with text illustrating how annotation is loaded in page
The storyboard viewer is more interactive. It renders the entire image in an OpenSeadragon object. The user is given a toolbar equipped with an auto-run button for automatically paging through annotations and various other navigation tools for displaying and exploring annotations. Additionally, there are zoom tools for inspecting the full image. Like the image viewer, the storyboard viewer has settings including changing the auto run interval, change the viewpoint from zoom to pan, change the text position, text to speech and more. A list of settings be found on this page: https://ncsu-libraries.github.io/annona/storyboard/#settings.
In the video below the same list has been loaded into two different websites and has been connected to a web socket server. The window on the far left is a receiver. The two windows next to it are the same URL and are the controllers. The receiver can navigate within the viewer if the toolbar is enabled but it will not communicate with any other webpage connected. The controller on the other hand will communicate with all websites connected to the web socket server and will send commands to all connected websites.
Additionally, the multi storyboard viewer allows for comparing two or more annotations in the same viewer. It has all the functionality and settings of the storyboard viewer but allows for comparison.
While I see a lot of uses for this JavaScript library, one of the problems I came across in initial testing was creating annotations is difficult without an annotation server. I was able to find a really good tool called annotate developed by Marii Nyrop, which allows you to download annotations created in a Mirador viewer. However, each annotation list has to be downloaded manually and placed in a specific folder and a rake task has to be run in order to serve and save the annotation. What I ended up doing was taking her existing repository and adding a flask server that allowed for the annotations to be written with a push of a button. Additionally, I added a vagrant box that has the site dependencies installed to reduce installation issues. Another problem I came across when working on this project is a lot of institutions only make use of the IIIF image server. Mirador, which is the viewer used in the annotate tool, requires a manifest created by the Presentation API. This reduced the number of IIIF enabled images that could be annotated. In order to provide greater usability I made use of a library called Annotorious that allows for annotations on images and added it to the site to allow for images without a manifest to be annotated.
However, I noticed these two platforms had very few fields. Mirador only allows for a main text field and tags. Annotorious, without some major development, only provides an additional author field. The problem is the annotation data model allows for more options. Text direction, language, choice fields, and rights information are some of the few fields available in the data model. When thinking and talking to other people about use cases and potential implications of this project, ownership was a real concern. Without an interface for entering creator and rights information annotations would have serious ownership questions. I have always seen these annotations having a great reuse factor and collaborative functionality, but rights and authorship are essential to making these more widely usable. However, it did not make sense to apply such a rich data model into the existing image editors. Instead I started developing an annotation editor that would be served from a web address that would allow users to edit annotations and then Download or Write to an API the endpoint. An example can be seen here: https://peaceful-depths-13455.herokuapp.com/annoeditor/render_anno?annotationurl=https://dnoneill.github.io/annotate/annotations/wh234bz9013-0001-list.json. It is still in development and it not nearly as robust as I would like it to be but it is a nice first step to at least providing language, rights and creator fields. Additionally, I see this tool as providing additional functionality for correcting OCRed text.
How did you decide on which technologies to use in your projects? How did your decision affect the direction of the work?
The biggest considerations for choosing technologies are: if it’s open source, if it meets the needs of the project, and how much documentation exists.
Sometimes, as with this project, it is also an opportunity to experiment with new technologies. For the JavaScript library I explored Vue CLI for creating the library because it provided command line tools that allowed for bundling code into a JavaScript library. I had previous experience using Angular, a similar framework, so it did help with the learning curve on this project. The use of the framework allowed for easier bundling and testing as opposed to writing straight JavaScript code.
For the local annotation server I was building on someone else’s tool that was built on top of Jekyll. I have done a lot of work with Jekyll so the codifying was simple enough and because Jekyll is one of the easiest frameworks to dynamically serve a site with GitHub pages it was the right tool for the job. Flask was chosen because I have some familiarity with it and it is one of the most lightweight servers. Since all it was used for was an endpoint I wanted something as lightweight as possible and Flask is run from a single file.
For the annotation editor I am using Ruby on Rails. I am actually more familiar with Python, but Ruby is what is used in my department so I decided it to be a really good opportunity to help me learn Ruby.
How has the project changed and evolved over the process?
The project has really evolved with my understanding of what is available within the IIIF community and the data structure of annotations.
My original mandate was to create an application that could view the image section of an annotation. There was, of course, room for continued development on the JavaScript library, but the other two projects came out of what I saw as a lack of open and easily usable resources. It was really important that these tools to be usable for people with no technical experience.
Also, while there are a couple of other resources that can provide storytelling, Storiiies and Digirati’s annotation playground and ocean liners are some examples, they both require the user to have a manifest with links to the annotations. I believe that the manifest requirement paired with the method of using these tools (changing the manifest in the URL) lacked a certain amount of flexibility. When developing this application I wanted it to be highly flexible and customizable. In addition to the optional settings, the viewers are fully customizable with CSS styling. The can be easily embedded in a web page and serve a variety of data models.
If you had to describe the project in 5 words, what would they be?
annotations, IIIF, storytelling, discovery, research
How can we find and use these tools?
The JavaScript library has documentation on how to implement each viewer located here: https://ncsu-libraries.github.io/annona/.
The local annotation server is located here: https://github.com/dnoneill/annotate and the instructions on how to install and host are located here: https://dnoneill.github.io/annotate/help/running-locally/. The demo site also has a page with a list of institutions that have IIIF images and links to the repositories. It also includes instructions on IIIF resources included with Wikipedia, Internet Archive, and ContentDM.
The annotation editor is located here: https://peaceful-depths-13455.herokuapp.com/annoeditor and is currently in development so the link will change eventually. I will make sure users know where the production version will be going before I move into production.
I am fully open to any feedback any or all of these projects. If you would like to provide feedback or functionality requests please fill out this short google form https://forms.gle/fGin3pjczcgFd9AZ8 or open an issue in the GitHub repos.